
While it is always important to think about time and cost efficiency, some issues are only noticeable with scale and increased complexity. Build systems like CircleCI offer many configurations but reach their limitations in the context of a mono repo. This article will provide you with a better understanding of these limitations, and show you how to overcome them utilizing CircleCI’s latest functionality in combination with custom tooling.
The Problem
At Credit Karma, we have 3 variants of the iOS app, built specifically for each of the different countries we serve. To simplify dependency management for native development, the Native teams opted to use a mono repo to house all of our iOS code. This meant that there were 30+ iOS engineers across different teams, working on different parts of separate applications, all working out of the same repository.
Our codebase is structured into 30+ different modules, with a small subset shared between all applications. While the move to a monorepo simplified dependency management and code sharing, our CI infrastructure was struggling to keep up with the additional load. We were running the entire testing suite for every single commit, regardless of the change. With a relatively large testing suite, this incredibly inefficient strategy made it difficult to merge pull requests.
Here’s an example of the dependency structure for one of our iOS apps. For example, an isolated change to `Module6` meant that we were running the tests for all modules, including the ones not even used in this particular application – how inefficient!
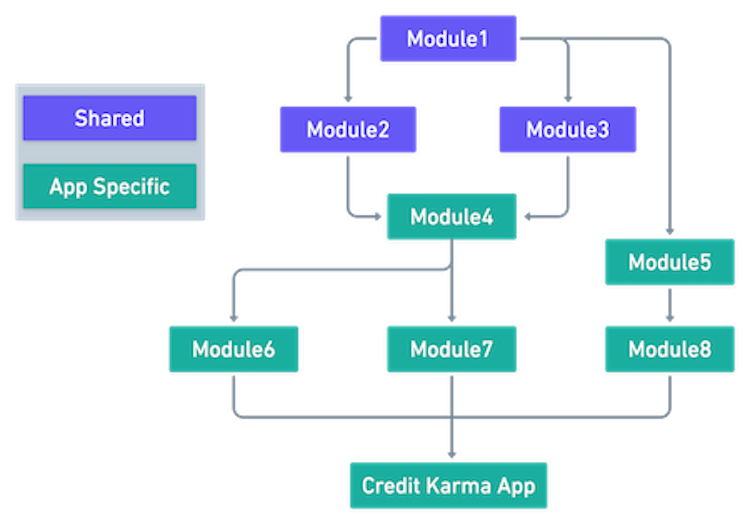
Generally speaking, the default CircleCI tooling is designed to work for a single repository with a single application, and with the shift to a monorepo, we needed more control over our workflows & jobs. This post will cover the additional tooling that we implemented at Credit Karma to support this goal:
Run the tests only for the modules that may be impacted by a given change.
Why it matters?
In the past, we’ve thrown more machines at the problem. This was masking the underlying problem, and was only a temporary bandage to the root problem increasing our infrastructure cost. Like most companies, Covid has caused us to re-evaluate our costs, and trim the inefficiencies where possible, and these efforts not only reduce the infrastructure costs, but also reduce the time it takes to run the testing suite on PRs, effectively saving our developers more time.
The Process
Current State
Each module has its own set of tests, and we use a “pre-build” job which is responsible for building all of the test runners for each module. Each module then executes the tests in parallel as shown in the image below:

Part I – Conditional Workflows
With a clear separation in applications and modules (US/International/Shared), we began looking for ways to conditionally run a workflow based on the changes. We came across this medium article which leverages pipeline parameters, which were officially introduced in the Circle CI v2 API, in December 2019:
Pipeline parameters are typed pipeline variables that are declared in the parameters key at the top level of a configuration. Users can pass parameters into their pipelines when triggering a new run of a pipeline through the API.
We define the pipeline parameters in the beginning of our configuration file, and each pipeline parameter corresponds to a workflow we intend to trigger via the CircleCI API. To illustrate the simplest case, we’ve defined a single pipeline parameter, trigger, which has a default value of `true`, that tells CircleCI to always run the trigger workflow unless explicitly skipped. To link the pipeline parameters with the workflows, we can use the `when: << pipeline.parameters.trigger >>` condition to conditionally run a workflow.
version: 2.1 |
This `ci` workflow has a single job, `trigger-workflows`, which is solely responsible for triggering other workflows.
- First, we use a custom command,
`checkout_folder`to only check out the contents of the.circleci/ directory, to save time - Next, we install Jack, an in-house command line utility written in Python used to share scripts & other resources between both repositories
- We then call the `jack ios ci trigger workflow` command, with the following two files:
- dependencies.json – simple json object depicting dependency structure of app and connecting workflows (more on this later)
- config.yml – a copy of the circle ci config file
Jack (of all trades)
The `trigger workflow` command is responsible for the following:
- Determining which workflow to run based of the changed files
- Determining jobs will be skipped
- Reporting “success” to GitHub status check for “skipped” jobs
- Triggering the correct workflow using the CircleCI API with pipeline parameters
In order to understand the dependency structure of the project, we introduced a simple json object which can be adopted by any repository using any language. It looks like this:
{ |
Each object in this file represents a “package”, which has a distinct `path_regex` and a corresponding workflow (pipeline parameter). Lastly, we express the dependencies in an array, which contains the names of other dependent “packages”. We need this information to build a dependency graph to determine which workflow to trigger.
Trigger Internals
Let’s take a look at what core logic in the `jack trigger workflow` job:
def trigger_workflow(packages: [Package], circle_config: dict): |
This logic is pretty straightforward, as we parse and extract all jobs from the Circle config, and then retrieve a list of changed files from the GitHub API. Using this info along with the supplied dependencies.json file, we build a dependency graph and determine which workflow to trigger. We then determine which jobs will be skipped and report them back to GitHub as successful.
Part II – Conditional Jobs
Having the ability to split workflows based on changes isolated to a single app is already a huge time saver, especially if the workflows deviate substantially in overall run time.
Changes are oftentimes limited to specific feature modules which might have just few or even no other dependencies. We thought it would be great to just skip jobs which aren’t impacted by given changes.
As you can guess, our solution for this involves Jack, and some CircleCI configuration magic. Let’s start with everything in Circle first.
Circle Configuration
CircleCI doesn’t offer any mechanism to conditionally run jobs in a workflow. However, CircleCI does allow you to conditionally exit a job without failing. From the CircleCI documentation, we can use `circleci-agent step halt`. While we still must spin up the executor, we can at least exit early to avoid running tests on non-impacted code.
What we would need is something like this:
run: | |
This looks great, but there are still a few more problems we need to solve:
- Determine the affected jobs based on the code changes (we’ll cover this in part II)
- Pass this information down to each job on CircleCI
As we want to cover the CircleCI part of this solution first, we’ll presume Jack already has this information. Jack determines which jobs can be skipped and writes them to a simple .txt file made available to all jobs.
Modules not impacted by changes: |
The usual way to pass information to downstream jobs in CircleCI would be persisting the data to the workspace and then restoring it in every job. Since we use the workspace for many other things, we needed something lightweight and fast. As we’re only seeking to pass around one simple text file, re-purposing the CircleCI cache functionality allowed us to achieve just this. We just use the current commit hash to ensure this file is only used for the given PR the workflow is running for.
- run: |
As mentioned above, we have to properly match the module name to the job name. In our example we were just assuming the job name having the same name as the module in our `jobs_to_skip.txt` file. We could also have a parameter for each job containing the module name to keep the actual job name more flexible.
Caution – Any mistake in naming or of job or parameter, would break this system. This can be solved by linting the Circle config to ensure consistency between job names and module names.
Determining Which Jobs to Skip
For the conditional workflows, we created a static `dependencies.json` file which encodes the package information for each application as well as its dependencies. Any change in a given module could have an impact on it as well as its dependents, which must be properly tested!
Our dependency file which we’ll pass in to Jack will look something like this:
{ |
We opted to use XcodeProj to create a script to parse our project files for every module and generate this dependency graph.
Utilizing swift package manager allowed us to cache this code in our Circle process to generate the dependency.json file for every PR. If the dependency is explicitly defined in the module project, it’s fairly straightforward to retrieve the information using XcodeProj:
let dependents = pbxproj.targetDependencies.compactMap { $0.name } |
Running the package script on Circle is simple:
- restore_cache: |
Using this dependency graph representation as a parameter allows Jack to determine the jobs which can be skipped and return the above mentioned text file which can be passed to the downstream jobs.
- run: |
The Outcomes
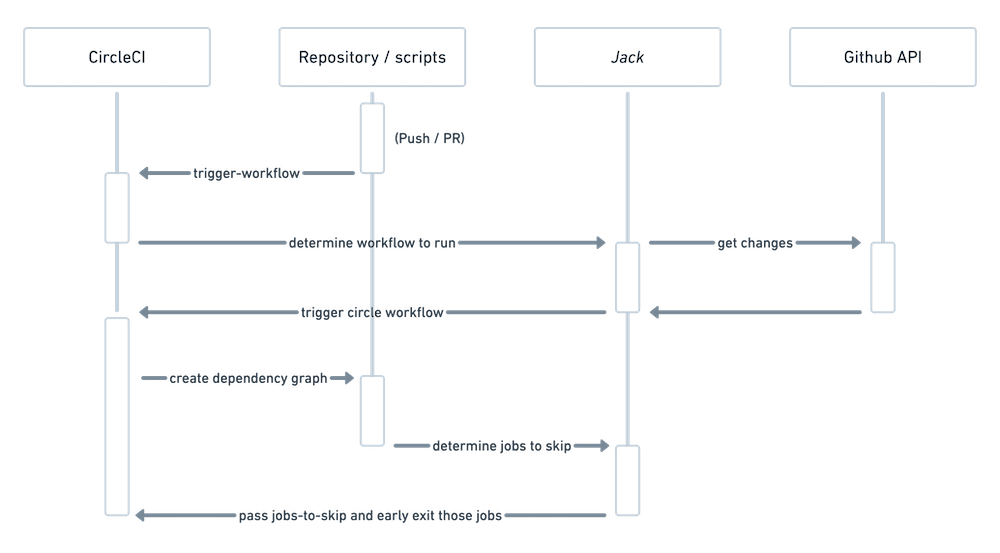
The following diagram depicts all parts of the system and how they interact with one another:
Here’s a visual representation of a typical workflow before & after our changes. Previously a simple change would have caused the entire suite to run, taking over 2 hours. With the revised changes, that same change only took 37 minutes, almost a 75% decrease in total time.

Other Potential Benefits & Improvements
By introducing an additional job that essentially gates other workflows, we have additional control which enables us to employ some logic. Here’s a couple of things we did:
- Introduce a
`.circleignore`which behaves similarly to a`.gitignore`file and ignores any changes to the files in this file - Enable “Only Run with open PR” functionality. While this feature is available on CircleCI, we experienced some issues using it in conjunction with scheduled workflows
- Since we automatically generate the dependency graph on every commit, we’re also able to treat it as a linter to control the dependency graph and enforce structural guidelines
We’re very excited to continue to develop this tool internally, and have even discussed the possibility of turning it into a Circle Orb.



