
We use big data at Credit Karma for data science modeling and analytical reporting, which helps us assess the efficacy of our products and services. We process and store data in Google BigQuery at scale, and we do this with data security, data quality, data lineage and data management as our key requirements. These make up the cornerstone of our data governance program.
We have many different data sources — databases and data files — and we have a complex data pipeline. To manage and document these complex data assets, we built a browser-based application called Data Explorer that manages our Data Dictionary. This tool provides us with valuable metadata, which lets us automate much of our data governance processes. In fact, we have learned that the only way to manage petabytes of data effectively is with metadata, and the Data Dictionary and Data Explorer have made this possible by crowdsourcing the knowledge about these data sources.
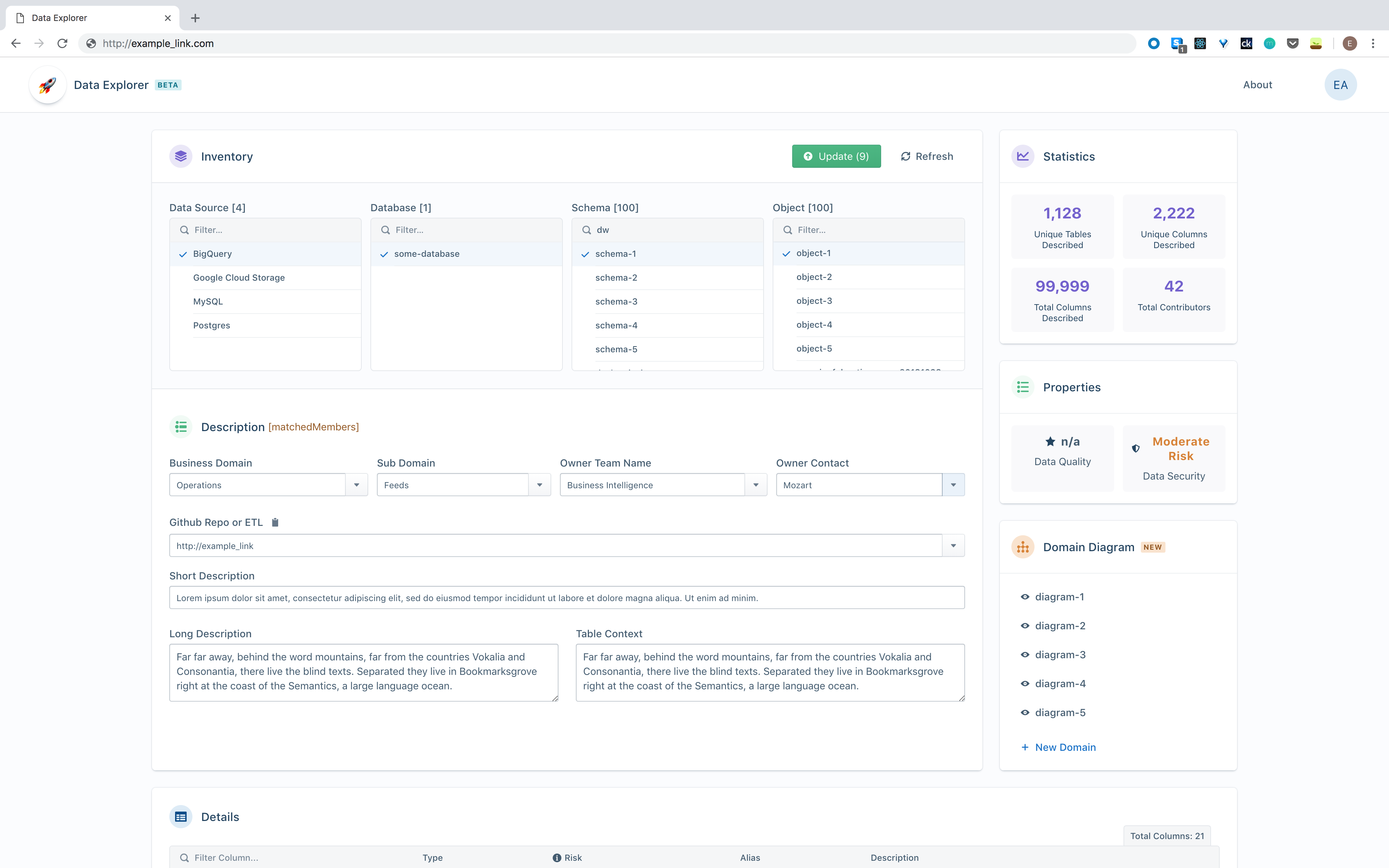
The Data Explorer presents an inventory of data sources, with descriptions of every database table and system file at the column/field level. We also show the Github repo.
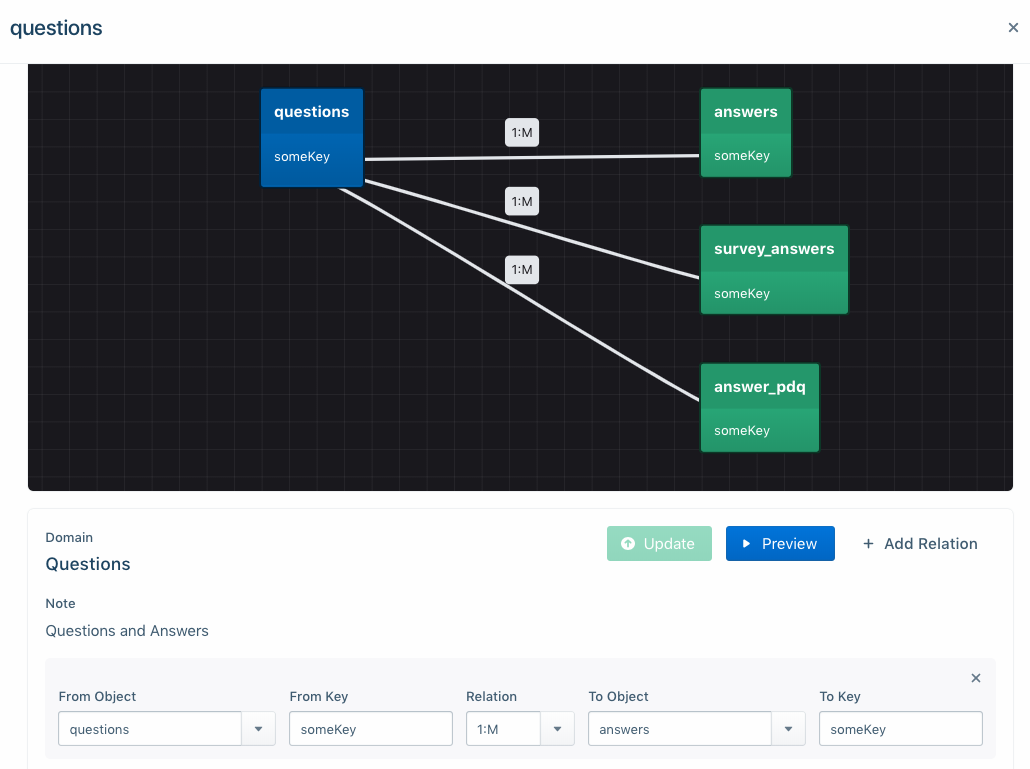
Domain Data Modeler
We learned that there are currently no books on big data modeling, so we studied how people worked with big data and found that they primarily deal with subdomains — basically a small handful of tables or files at a time. And we are very pleased that we found that data modeling at the subdomain level works well in a big data environment.
The Subdomain Data Modeling feature shows the tables that are related to the table you’re currently viewing. This gives you complete contextual information about a table, the tables to which it relates and the source of the data in that table.
Using this subdomain approach, our users enter the team and person contact information, so we know who owns which subdomains. We use crowdsourcing to add content to the Data Explorer; each team contributes knowledge of its respective subdomain.
When people post a question on one of our forums, we point them to the Data Explorer site and work with them to find information about the data objects they need to work with. If they find the data of interest is not yet described and documented, we add them to our team of “editors” so they can contribute to the documentation effort. Our approach is reminiscent of Wikipedia’s, and it works very well. We find that many data owners are passionate about “paying it forward” in their subdomain, and they really enjoy adding descriptive content so others can easily find what they need.
In addition to the textual data descriptions, we also check that the data meets both security and quality thresholds. As soon as a data file hits our staging area, a Data Loss Prevention (DLP) engine (Google DLP) scans the file for any issues and assesses its security risk level. It also assigns an alias if the field name is cryptic. A good example is age: If a column of data is named X30W34, the DLP engine scans and assesses the data values. If the numeric range is, say, 18 to 100, it might suggest that X30W34 represents a person’s age. This process trains the engine and develops increasingly sophisticated business rules over time.
For security reasons, we scan every field in every file at ingestion time. We set risk ratings for the scanning engine so it tags each column with a security risk rating. A composite data security rating is set in our dashboard, which is the highest level of security risk for all fields in that file. If one column has a high risk rating, then the dashboard shows a high risk rating for the entire file.
In a similar manner, we use Apache Griffin to assess the quality of the column data. We configure Griffin with business rules in configuration files; these rules are typically regular expressions. The output of the scan is an average data quality score from zero to 100%, which is subsequently displayed in the Data Explorer. This raises the visibility of low-quality data so we can improve the ingestion process over time.
We learned three key lessons building the Data Dictionary and Data Explorer:
- Big data can only be managed with effective metadata
- People tend to work in small subdomains within the larger data store
- Crowdsourcing is an effective bottom-up way to discover the metadata and keep it up to date.



